原文地址),如有侵权,请联系删除。
近期即梦上线了 AI 图片生成文字的能力,在生成海报、封面以及各种场景下渲染文字效果是非常不错的。最开始AI生成的图片中,涉及到文字的基本都是不能看的乱码,需要针对性训练优化才能做到生成清晰的文字并融入图片。那这里是怎么做优化的?对这个原理比较好奇,尝试通过几篇公开论文学习下相关实现思路原理。
大致思路:Recraft
目前生成文字(英文)最好的模型是 Recraft,官方有篇文章 《How To Create SOTA Image Generation with Text: Recraft’s ML Team Insights》介绍了模型训练的大体过程,挺适合简单了解大致思路的,简单复述下。
首先说明下为什么图片生成文字容易乱码?
- 一是数据量不足:图片生成模型是通过大量图片+图片描述去做训练,而大部分图片的描述是不怎么包含图上的文字的,比如拍一个街道建筑图,图上会有很多店面的名字文字,图片描述可能就是类似 城市/街道/红色招牌等描述,并没有把图上的所有文字放进去,模型只能在少部分相对简单的场景(比如图上只有几个字,图片描述中也有这几个字)中学习生成正确的文本,幻觉会比较严重。
- 二是文字的错误更容易被发现,相对于人物动作不协调、衣服花纹的差错,文字只要有一笔一划错误就很容易被人察觉识别为乱码,需要更精确的生成。
接下来看优化文字生成能力的大致流程:
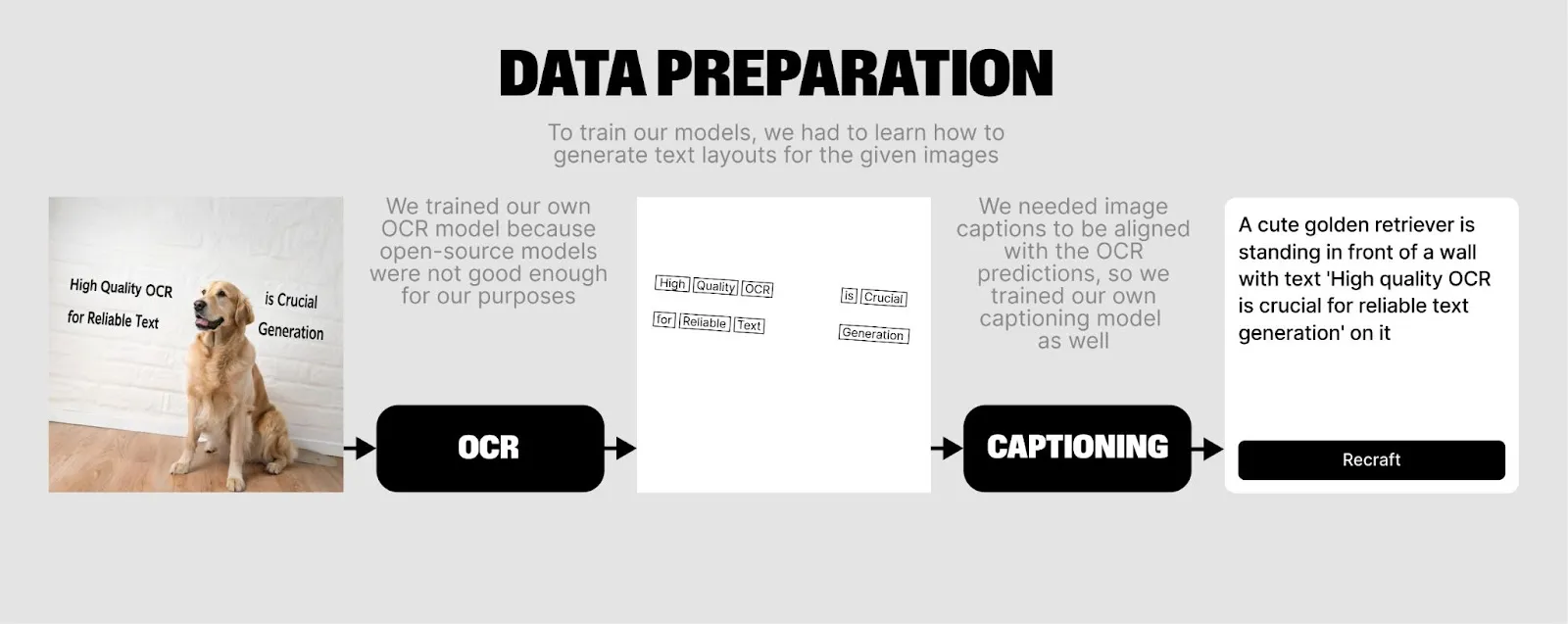
第一步,准备数据。准备大量的包含文字的图片,包括海报、封面、广告、Logo等,对这些图片进行处理。处理包含两部分,一是用 OCR 模型识别图像上的文字位置和文字内容,二是用多模态模型识别这张图的内容,输出描述文本。得到了海量的 图片 – 文本布局和内容 – 图片描述 组合的数据。
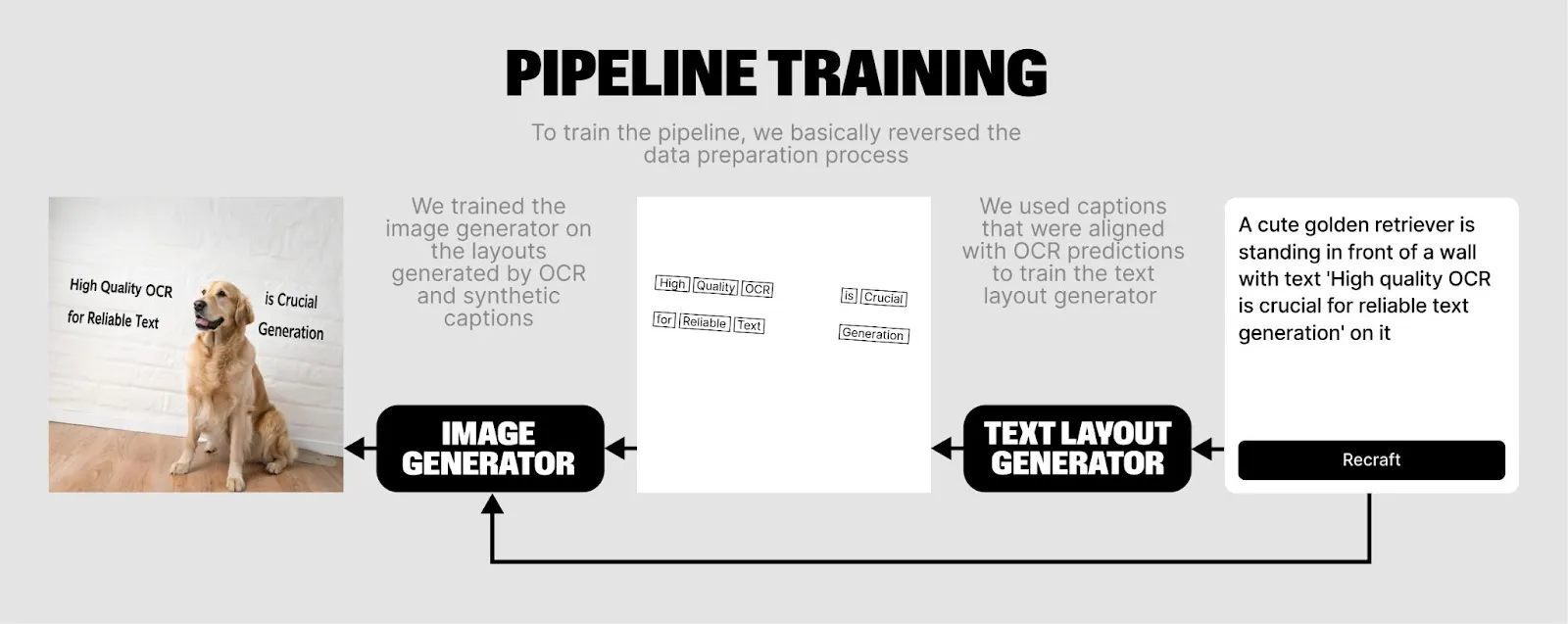
第二步,使用数据训练模型,跟第一步是反着的过程。先训练一个布局模型,可以通过输入 prompt → 输出文本布局+内容。再把 prompt 和文本布局输入生图模型,最终生成带文字的图片。
大流程就是这样,再稍微把其中布局模型展开一下:

输入 prompt 输出 文字内容+布局,用的是一个大语言模型(LLM),定义了一个输出的文本格式,包含文本内容和这些文本的坐标。同时还会根据文本和坐标数据,用文字渲染工具画张图片出来。
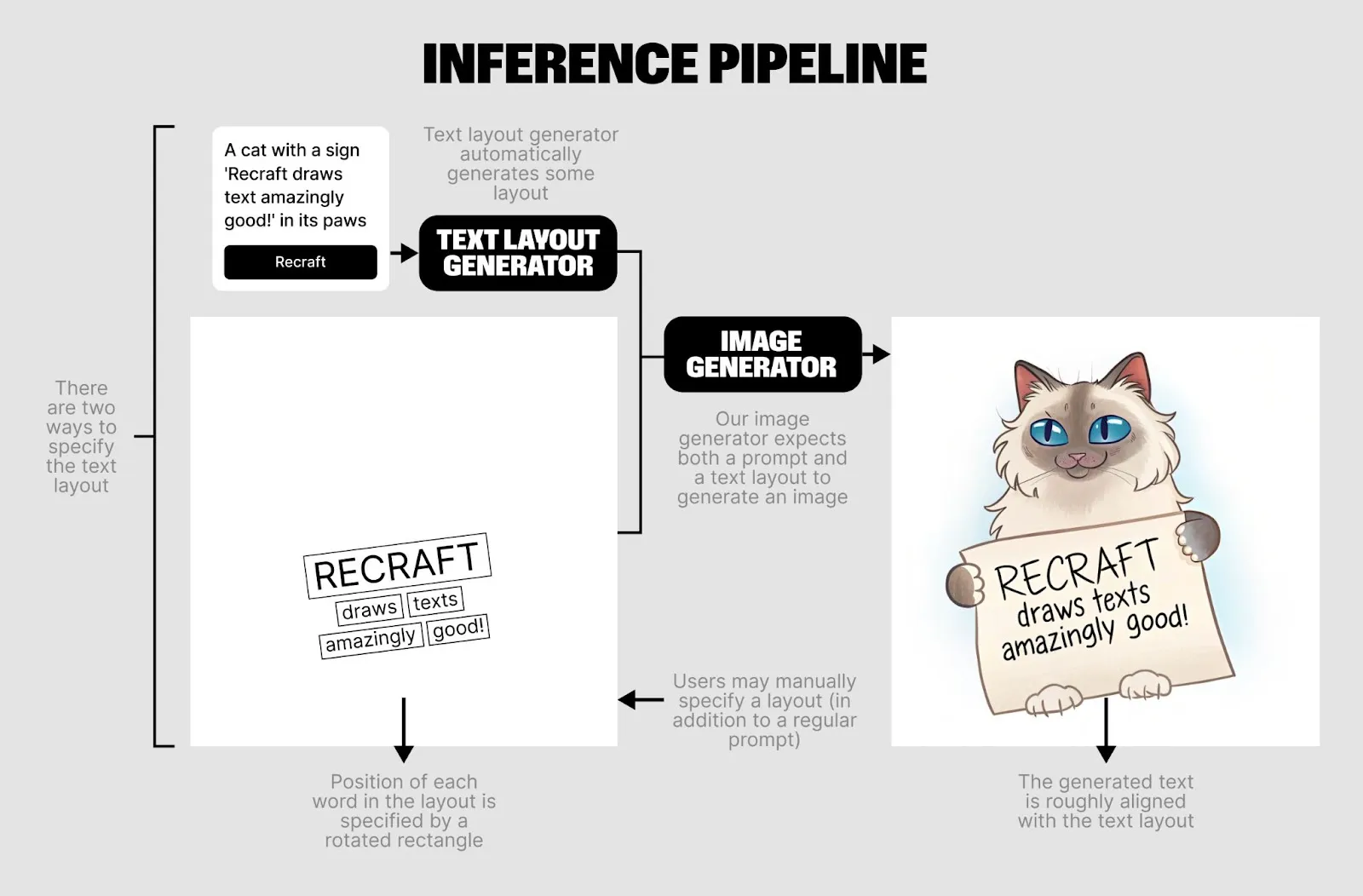
这张渲染出来的文字布局图会作为生图时的参考,用类似ControlNet 的方式作用在生图过程中,最终生成图上的文字。
这是个大致流程,文中没有展开里面模型架构的一些细节,原文上表示思路基于 TextDiffuser2,但看起来思路上跟 GlyphControl、TextDiffuser、TextDiffuser2 都有关系。
各方案大的思路都差不多,基本都是分两步,生成文字布局信息,再作用在生图过程中,主要是模型架构不同,以及数据集质量不同。下面看看这些相关的论文和一些模型细节。
GlyphControl
先看看相对简单的 GlyphControl,23年11月的论文,基本就是一种 ControlNet,跟边缘轮廓、姿态等 ControlNet 没太大差异。ControlNet 的相关介绍可以看回这篇。
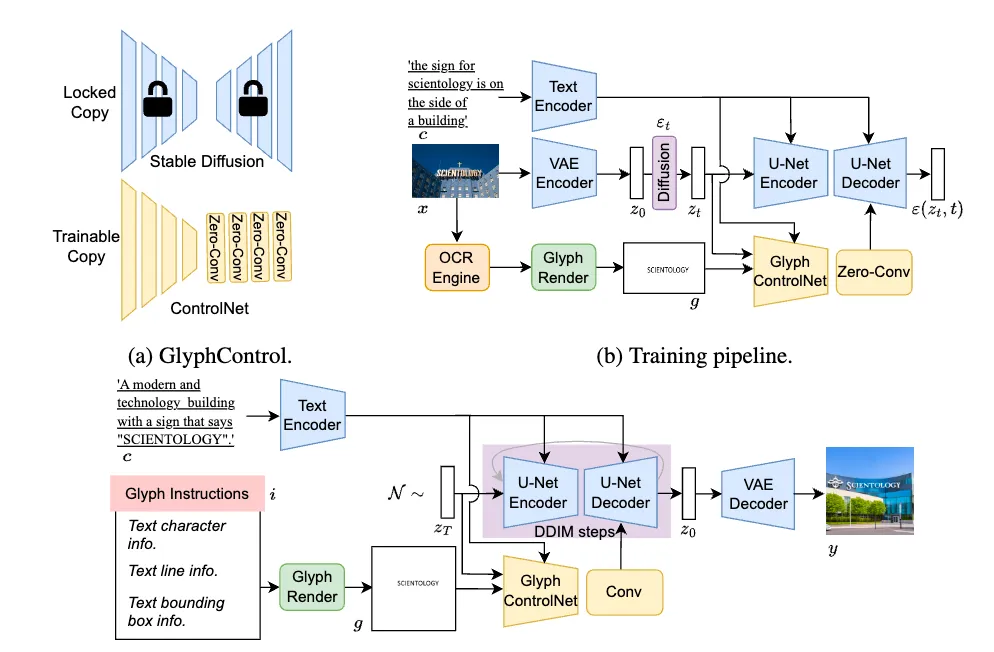
- 训练阶段: 找一批带文字的图片,用OCR 识别文字内容和位置,再渲染出一张白底黑字的图片,将图片描述和这张白底黑字图片一起进入 Glyph ControlNet 网络训练。这个白底黑字的图片就是参考图,跟边缘轮廓/姿态等其他 ControlNet 的参考图作用和流程都一样。
- 推理阶段: 分两部分输入,生图的 Prompt 和白底黑字参考图,这张参考图看起来是要用户自己另外准备的,可以直接画一张白底黑字的图,或者描述文字内容、行信息、大小位置布局,用工具生成白底黑字参考图,再和 prompt 一起去生成相应的带图的文字。
- 效果: 文字能较准确生成,但没有控制字体样式和文本颜色的能力,泛化性会比较差。布局和位置需要额外输入,产品化实用性低一些。
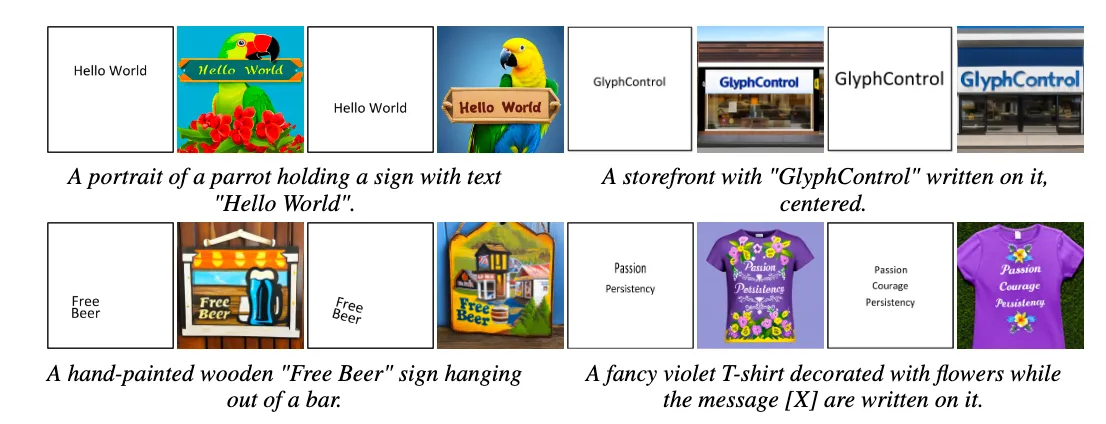
疑问: controlNet 23年2月出现,为什么11月才有人用于改进图片文字渲染,ControlNet作者自己不试试呢?
还有一篇更直接的,直接用 ControlNet 的边缘轮廓做文字生成,也不用自己训练,做了个评测: 《Typographic Text Generation with Off-the-Shelf Diffusion Model》
TextDiffuser
TextDiffuser 是23年10月的论文,跟上面 ControlNet 的思路有差异:
- 不用准备参考图,用一个模型从 prompt 中推断文字布局。
- 直接在生图扩散模型中训练,非 ControlNet 插件的形式。
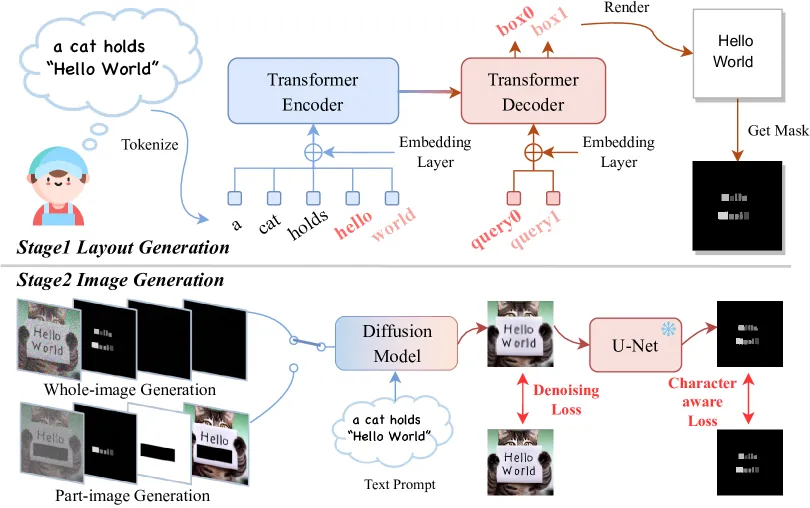
流程
- 布局生成:先根据 prompt 生成逐个字母的文字形状 mask 图。用一个 transformer 模型(非LLM)理解输入的语义,识别出图上要画哪些文字,这些文字在画布上应该是在哪个位置,获得每一个字符在画布上的box位置,再用字体渲染库(如pillow)把这些文字渲染上去,生成这些字符的遮罩表示(Mask)。
- 图像生成:将上一步得到的字符遮罩输入扩散模型,参与引导扩散过程,使图片能在遮罩对应的位置生成对应的字符形状。
训练
- 数据:作者从各处收集了1000万张带有文字的图像-文本对,称为MARIO-10M,主要来源是开源的LAION-400M,从中筛选带文字的高质量的图,也对数据进行了处理,包括文本检测识别、字符级的位置数据、原有的图片描述文字等。
- 布局阶段:会使用这个数据集去做训练上面提到的 transformer 模型,输入是图片描述文字,输出是每个字符的 mask 遮罩。在数据集中,每张图片的描述、以及每张图片经过 OCR 识别处理后字符的遮罩位置都有,模型就能学习到对不同的图片描述,对应的最终的文本位置和形状应该是怎样的。
- 图片生成阶段:这个数据集也会在扩散模型的基础上去做进一步训练,在这过程中 U-Net 的参数是冻结的,猜测是避免核心生图能力被破坏?训练过程中只会修改扩散模型 U-Net 以外的其他模块参数,整个网络还是能学习拟合到数据集里 图片描述(prompt) + 字符遮罩数据 → 带文字图片 这里的对应关系。
这整个过程,就是为生图增加信息量,布局阶段渲染的每个字符的 mask 是很大的信息量来源,引导图片扩散方向不飘。
效果
相对未针对性训练的生图模型,能生成合理清晰的文字,在给定图像补充文字上效果也不错,也能做到控制文本颜色了,但字体多样性差一些。


TextDiffuser2
TextDiffuser 有个问题,它第一阶段产生的文字 mask 是用单一字体渲染的结果,用这个 mask 引导生图,结果是生成的结果字形的多样性比较差,生成的文字倾向于规整,手写或艺术字很难出现,GlyphControl也有同样的问题。另外 TextDiffuser 布局转换器对用户输入 prompt 的理解能力也有限。
TextDiffuser2 差异在于:
- 布局模型用大语言模型去替换。LLM 能表现出比较强的语义理解布局规划能力,用一个 LLM 去理解 prompt 转化为对应的布局格式,效果会更好。
- 生图阶段,对扩散模型中的语言模型(clip)和 U-Net 都做了训练。
训练
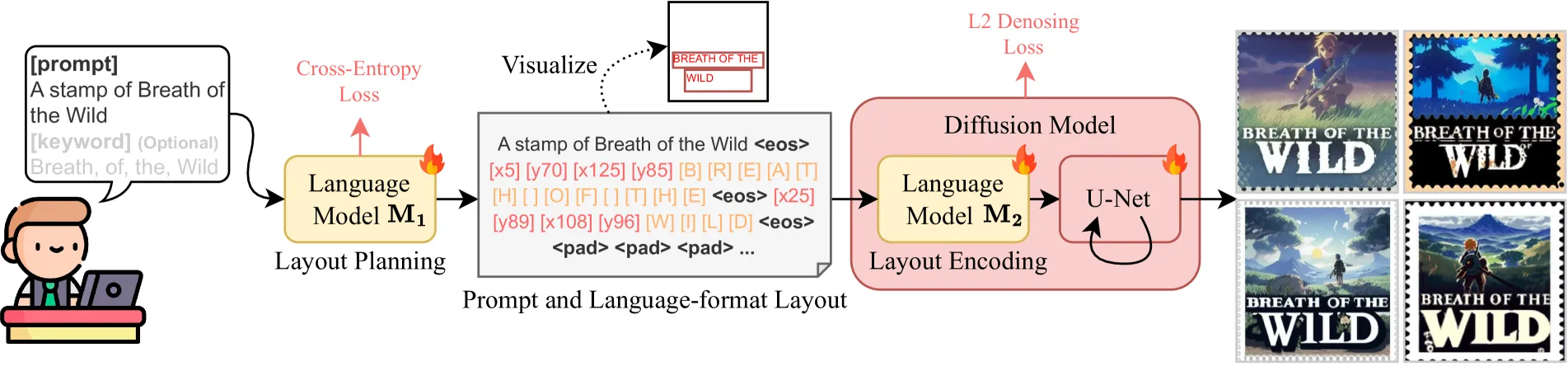
布局模型
- 使用 LLM vicuna-7b-v1.5 模型进行微调,训练用的还是前面的 MARIO-10M 数据集,拿这个数据集每张图对应的描述文字作为输入,用 OCR 把每张图片的内容和位置信息提取出来作为预期输出做训练。
- 这里自定义了布局的格式,一个关键词以一组坐标和字母组成,比如 [x25][y89][x108][y96][W][I][L][D],两个坐标表示方块左上右下两个点。每个字符单独标记,会比去做BPE分词标记效果好。
- LLM在学习了大量文字对应图片的构图后,可以从语义推理这些文字的构图应该是怎样的,同时 LLM 自身也能很好理解哪些词是关键字,哪些词应该在同一行。比如上图的 旷野之息邮票 a stamp of Breath of the Wild,LLM 可以学到图上的文本应该是 Breath of the Wild,而对于邮票比较好的布局是上下两行,有个关键字 Wild 突出,得出相应的布局数据。
- 根据论文描述,5000个数据量的训练效果是最好的,可能数据多了反而过拟合效果不好。
生图模型
- 直接在扩散模型中训练,图上的 M2 是扩散模型里的 clip 文本模型,布局内容和文本 prompt 会一起输入,U-Net 也参与了训练,继续在用 MARIO-10M 数据集做训练。为什么这种方式训练效果好,文中没怎么提到。
效果
TextDiffuser2 的多样性会好一些,字体形态多样。

总结
还有一些其他方案,例如 GlyphDraw、AnyText等,大原理差不多,不展开多说了。最后,用 notion AI 总结下本篇文章:
AI 图片生成文字主要有以下几种方案:
- GlyphControl: 通过白底黑字的参考图来控制生成文字的位置和内容,实现简单但泛化性较差。
- TextDiffuser: 采用两阶段方案 – 先用 transformer 模型生成文字布局 mask,再用扩散模型生成最终图像。但生成的字体样式比较单一。
- TextDiffuser2: 改进了 TextDiffuser,用大语言模型替代布局生成,并对扩散模型进行更全面的训练,使生成的文字样式更加丰富多样。
这些方案的核心思路都是:
- 准备大量包含文字的图片数据集(如广告、海报等)
- 设计两阶段架构:先生成文字布局,再生成最终图像
- 通过不同的技术手段(如 ControlNet、LLM等)来提升生成效果
目前 TextDiffuser2 的效果最好,既保证了文字的准确性,又能生成多样化的字体样式。Recraft 借鉴了 TextDiffuser2 和 GlyphControl。